自己投資としてチャレンジしている内容を Blog で公開しています。今回は Apache Spark の Spark SQL を利用した SQL クエリを実行するコードを紹介します。
▼1. Spark SQL の利用
Spark SQL を利用すると Relational Database で利用する SQL 文のような select クエリなどでデータの操作が可能です。ある session の中でのみ利用可能な temporary view の作成や、すべての session から参照できる temporary の View を globa_temp データベースに作成することもできます。
▼2. 事前準備
2-1. Apache Spark クラスターを作成
詳細は以前 blog で紹介した下記サイトを参照ください。
Apache Spark インストール – 3 ノード No.29
2-2. Spark で処理するデータを HDFS 上に配置
2-2-1. ホームディレクトリの作成後、その配下にディレクトリを作成
既に作成されている場合は飛ばします。
hdfs dfs -mkdir -p /user/hadoop
hdfs dfs -mkdir appbox2-2-2. ファイルをディレクトリにコピー
Spark インストール時に同梱されている people.json を 作成したディレクトリ appbox にコピーします。あとで行う wordcount の入力のファイルとして利用します。
sudo cp ~/spark/examples/src/main/resources/people.json ./
hdfs dfs -put people.json appbox2-2-3. コピーしたファイルの確認
hdfs dfs -ls appbox
--- 出力結果の例 ----
Found 1 items
-rw-r--r-- 1 hadoop supergroup xxx 2021-07-04 10:00 appbox/README.md
-rw-r--r-- 1 hadoop supergroup xxx 2021-07-09 10:00 appbox/people.json
--------▼3. Spark SQL を利用した Dataset の操作
以降のコードでは SparkSession を作成後、JSON 形式のデータを DataFrame に取り込み、条件に合わせてデータを表示しています。
3-1. Sparktest のフォルダおよび、ディレクトリの作成
mkdir ~/SparkSQLQueries
sudo chown -R hadoop ~/SparkSQLQueries
cd ~/SparkSQLQueries以下のような階層でフォルダおよびファイルを作成していきます。
./pom.xml (3-2)
./src
./src/main
./src/main/java
./src/main/java/SparkSQLQuerieseg.java (3-3)3-2. pom.xml を作成し、Sparktest 配下 (./pom.xml) に配置
<project>
<groupId>edu.berkeley</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>3-3. SparkSQLQuerieseg.java を作成し /src/main/java/ 配下に配置
/* SparkSQLQuerieseg.java */
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import static org.apache.spark.sql.functions.col;
import org.apache.spark.api.java.function.MapFunction;
public class SparkSQLQuerieseg{
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("Java Spark SQL Queries example").config("spark.some.config.option","some-value").getOrCreate();
Dataset<Row> df = spark.read().json("/user/hadoop/appbox/people.json");
System.out.println("Register the DataFrame as a SQL temporary view");
df.createOrReplaceTempView("people1");
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people1");
System.out.println("Displays the content of SQL temporary view.");
sqlDF.show();
}
}3-4. maven をインストール
(既にインストール済みの場合、飛ばします。
wget https://downloads.apache.org/maven/maven-3/3.8.1/binaries/apache-maven-3.8.1-bin.tar.gz -P /tmp/
sudo tar xzvf /tmp/apache-maven-*.tar.gz -C /opt/
/opt/apache-maven-3.8.1/bin/mvn -version
---
Apache Maven 3.8.1 (05c21c65bdfed0f71a2f2ada8b84da59348c4c5d)
Maven home: /opt/apache-maven-3.8.1
Java version: 1.8.0_292, vendor: Azul Systems, Inc., runtime: /usr/lib/jvm/zulu-8-azure-amd64/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.15.0-1113-azure", arch: "amd64", family: "unix"3-5. コンパイル
cd SparkSQLQueries
/opt/apache-maven-3.8.1/bin/mvn package3-6. 生成された jar を実行
spark-submit --class "SparkSQLQuerieseg" --master yarn ./target/simple-project-1.0.jar > simple-project-1.0.jarsqlquerieseg.log 2>&1出力したファイル simple-project-1.0.jarsqlbasic.log を確認すると、以下のような結果が得られています。
//simple-project-1.0.jarsqlquerieseg.log
2021-07-11 21:00:37,876 INFO cluster.YarnScheduler: Killing all running tasks in stage 1: Stage finished
2021-07-11 21:00:37,877 INFO scheduler.DAGScheduler: Job 1 finished: json at SparkSQLQuerieseg.java:12, took 0.268434 s
Register the DataFrame as a SQL temporary view
xxx
2021-07-11 21:00:38,321 INFO storage.BlockManagerMasterEndpoint: Registering block manager node01:46541 with 413.9 MiB RAM, BlockManagerId(1, node01, 46541, None)
Displays the content of SQL temporary view.
2021-07-11 21:00:38,799 INFO datasources.FileSourceStrategy: Pushed Filters:
xxx
2021-07-11 21:00:44,403 INFO cluster.YarnScheduler: Removed TaskSet 2.0, whose tasks have all completed, from pool
2021-07-11 21:00:44,409 INFO cluster.YarnScheduler: Killing all running tasks in stage 2: Stage finished
2021-07-11 21:00:44,409 INFO scheduler.DAGScheduler: Job 2 finished: show at SparkSQLQuerieseg.java:19, took 4.746346 s
2021-07-11 21:00:44,488 INFO codegen.CodeGenerator: Code generated in 49.264841 ms
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
2021-07-11 21:00:44,519 INFO server.AbstractConnector: Stopped Spark@6a96d045{HTTP/1.1, (http/1.1)}{0.0.0.0:4040}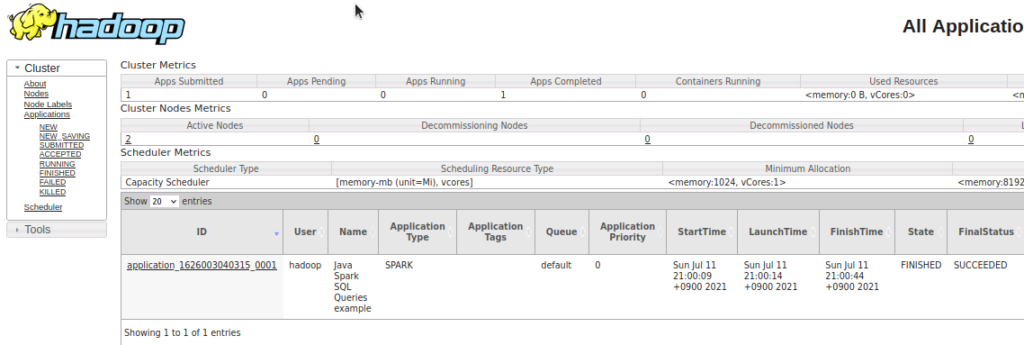
▼4. 参考情報
Getting Started – Spark 3.1.2 Documentation (apache.org)
以上です。参考になりましたら幸いです。