自己投資としてチャレンジしている内容を Blog で公開しています。今回は Apache Spark の環境で利用できる PySpark について紹介します。
▼1. PySpark とは
PySpark は、Apache Spark の環境で Spark の処理を行える Python コードです。Apach Spark をインストールした環境では、デフォルトで PySpark がインストールされています。環境変数に設定した {SPARK_HOME}/bin の配下に pyspark を確認することができます。
▼2. 事前準備
2-1. Apache Spark クラスターを作成
詳細は以前 blog で紹介した下記サイトを参照ください。
Apache Spark インストール – 3 ノード No.29
▼3. PySpark を使い、色々な方法で DataFrame を作成し、色々なタイプのファイル形式で保存
PySpark DataFrame API (pyspark.sql.SparkSession.createDataFrame) を使って、Table のような DataFrame を作成します。
DataFrame の作成方法は以下のように幾つかあり、それぞれ紹介します。
- A. 行のリストから作成
- B. タプルのリストから作成
- C. スキーマを指定して作成
- D. Pandas オブジェクトを利用して作成
3-1. 事前準備として、Pandas オブジェクトのライブラリーをインストール
sudo apt-get update
sudo apt-get install python3-pip
sudo python3 -m pip install pandas3-2. PySpark を起動するため pyspark のコマンドを実行
pyspark
(標準出力)
Python 3.8.10 (default, Jun 2 2021, 10:49:15)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
2021-10-04 12:22:30,989 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2021-10-04 12:22:34,184 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.8.10 (default, Jun 2 2021 10:49:15)
Spark context Web UI available at http://hostnamexxx:4041
Spark context available as 'sc' (master = local[*], app id = local-xxxx).
SparkSession available as 'spark'.3-3. 色々な方法で DataFrame を作成
DataFrame とはデータの集まりで、Relational Database の table のようなものです。
事前準備として、DataFrame の作成に必要なライブラリー datetime, pandas および pyspark.sql をインストールします。
from datetime import datetime, date
import pandas as pd
from pyspark.sql import RowA. 行のリストから DataFrame を作成
dfa = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
dfa
(結果)
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]B. タプルのリストから作成
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
dfb = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
dfb
(結果)
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]C. スキーマを指定して作成
dfc = spark.createDataFrame([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
], schema='a long, b double, c string, d date, e timestamp')
dfc
(結果)
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]D. Pandas オブジェクトを利用して作成
pandas_df = pd.DataFrame({
'a': [1, 2, 3],
'b': [2., 3., 4.],
'c': ['string1', 'string2', 'string3'],
'd': [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)],
'e': [datetime(2000, 1, 1, 12, 0), datetime(2000, 1, 2, 12, 0), datetime(2000, 1, 3, 12, 0)]
})
dfd = spark.createDataFrame(pandas_df)
dfd
dfd.show()
dfd.printSchema()
(結果)
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]
+---+---+-------+----------+-------------------+
| a| b| c| d| e
|
+---+---+-------+----------+-------------------+
| 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|
| 2|3.0|string2|2000-02-01|2000-01-02 12:00:00|
| 3|4.0|string3|2000-03-01|2000-01-03 12:00:00|
+---+---+-------+----------+-------------------+
root
|-- a: long (nullable = true)
|-- b: double (nullable = true)
|-- c: string (nullable = true)
|-- d: date (nullable = true)
|-- e: timestamp (nullable = true)
3-4. パーティションキーを指定して、色々なタイプのファイルにデータを保存
以降では 3 種類のファイルフォーマットでデータを保存する方法を紹介します。
- 3-4-1. CSV の場合
- 3-4-2. Parquet の場合
- 3-4-3. ORC の場合
3-4-1. CSV ファイルの場合
上の 3-3 の A で作成した DataFrame dfa を確認します。
>>> dfa.show()
+---+---+-------+----------+-------------------+
| a| b| c| d| e|
+---+---+-------+----------+-------------------+
| 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|
| 2|3.0|string2|2000-02-01|2000-01-02 12:00:00|
| 4|5.0|string3|2000-03-01|2000-01-03 12:00:00|
+---+---+-------+----------+-------------------+Partition Key を c 列とし、データを CSV ファイルに保存します。その後、保存した CSV データを表示します。
>>> dfa.write.mode("overwrite").partitionBy("c").csv("appbox/dfa",header=False)
>>> spark.read.csv("appbox/dfa").show()
+---+---+----------+--------------------+-------+
|_c0|_c1| _c2| _c3| c|
+---+---+----------+--------------------+-------+
| 2|3.0|2000-02-01|2000-01-02T12:00:...|string2|
| 1|2.0|2000-01-01|2000-01-01T12:00:...|string1|
| 4|5.0|2000-03-01|2000-01-03T12:00:...|string3|
+---+---+----------+--------------------+-------+hdfs のコマンドで保存先のフォルダをみると、Partition 毎にフォルダが作成されており、その Partition 毎のフォルダの配下に csv ファイル (.csv の拡張子) が保存されていることが確認できます。
$ hdfs dfs -ls appbox/dfa
Found 4 items
-rw-r--r-- 1 hadoop supergroup 0 2021-10-04 12:35 appbox/dfa/_SUCCESS
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:35 appbox/dfa/c=string1
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:35 appbox/dfa/c=string2
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:35 appbox/dfa/c=string3
$ hdfs dfs -ls appbox/dfa/c=string1/
Found 1 items
-rw-r--r-- 1 hadoop supergroup 47 2021-10-04 12:35 appbox/dfa/c=string1/part-00000-ed486552-7acf-4e38-9b6d-cf5a9e32c099.c000.csv
3-4-2. Parquet ファイルの場合
Partition Key を c 列とし、データを Parquet ファイルに保存します。その後、保存した Parquet ファイルを参照しデータを表示します。
>>> dfa.write.mode("overwrite").partitionBy("c").parquet("appbox/dfa_parquet")
>>> spark.read.parquet("appbox/dfa_parquet").show()
+---+---+----------+-------------------+-------+
| a| b| d| e| c|
+---+---+----------+-------------------+-------+
| 1|2.0|2000-01-01|2000-01-01 12:00:00|string1|
| 4|5.0|2000-03-01|2000-01-03 12:00:00|string3|
| 2|3.0|2000-02-01|2000-01-02 12:00:00|string2|
+---+---+----------+-------------------+-------+hdfs のコマンドで保存先のフォルダをみると、Partition 毎にフォルダが作成されており、 その Partition 毎のフォルダの配下に parquet ファイル (.parquet の拡張子) が保存されていることが確認できます。
$ hdfs dfs -ls appbox/dfa_parquet
Found 4 items
-rw-r--r-- 1 hadoop supergroup 0 2021-10-04 12:40 appbox/dfa_parquet/_SUCCESS
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:40 appbox/dfa_parquet/c=string1
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:40 appbox/dfa_parquet/c=string2
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:40 appbox/dfa_parquet/c=string3
$ hdfs dfs -ls appbox/dfa_parquet/c=string1/
Found 1 items
-rw-r--r-- 1 hadoop supergroup 1176 2021-10-04 12:40 appbox/dfa_parquet/c=string1/part-00000-529d6ea5-cb06-437e-a969-b6c04eccb680.c000.snappy.parquet
3-4-3. ORC の場合
Partition Key を c 列とし、データを orc ファイルに保存します。その後、保存した orc ファイルを参照しデータを表示します。
>>> dfa.write.mode("overwrite").partitionBy("c").orc("appbox/dfa_orc")
>>> spark.read.orc("appbox/dfa_orc").show()
+---+---+----------+-------------------+-------+
| a| b| d| e| c|
+---+---+----------+-------------------+-------+
| 4|5.0|2000-03-01|2000-01-03 12:00:00|string3|
| 2|3.0|2000-02-01|2000-01-02 12:00:00|string2|
| 1|2.0|2000-01-01|2000-01-01 12:00:00|string1|
+---+---+----------+-------------------+-------+hdfs のコマンドで保存先のフォルダをみると、Partition 毎にフォルダが作成されており、 その Partition 毎のフォルダの配下に orc ファイル (.orc の拡張子) が保存されていることが確認できます。
$ hdfs dfs -ls appbox/dfa_orc/
Found 4 items
-rw-r--r-- 1 hadoop supergroup 0 2021-10-04 12:46 appbox/dfa_orc/_SUCCESS
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:46 appbox/dfa_orc/c=string1
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:46 appbox/dfa_orc/c=string2
drwxr-xr-x - hadoop supergroup 0 2021-10-04 12:46 appbox/dfa_orc/c=string3
$ hdfs dfs -ls appbox/dfa_orc/c=string1/
Found 1 items
-rw-r--r-- 1 hadoop supergroup 595 2021-10-04 12:46 appbox/dfa_orc/c=string1/part-00000-fed8a648-d2ef-47ad-8c51-855fbf10c8f3.c000.snappy.orc
3-5. 最後に、上記 Spark の処理 (ジョブ) の実行履歴は以下のように 4040 もしくは 4041 ポートの Spark UI で確認
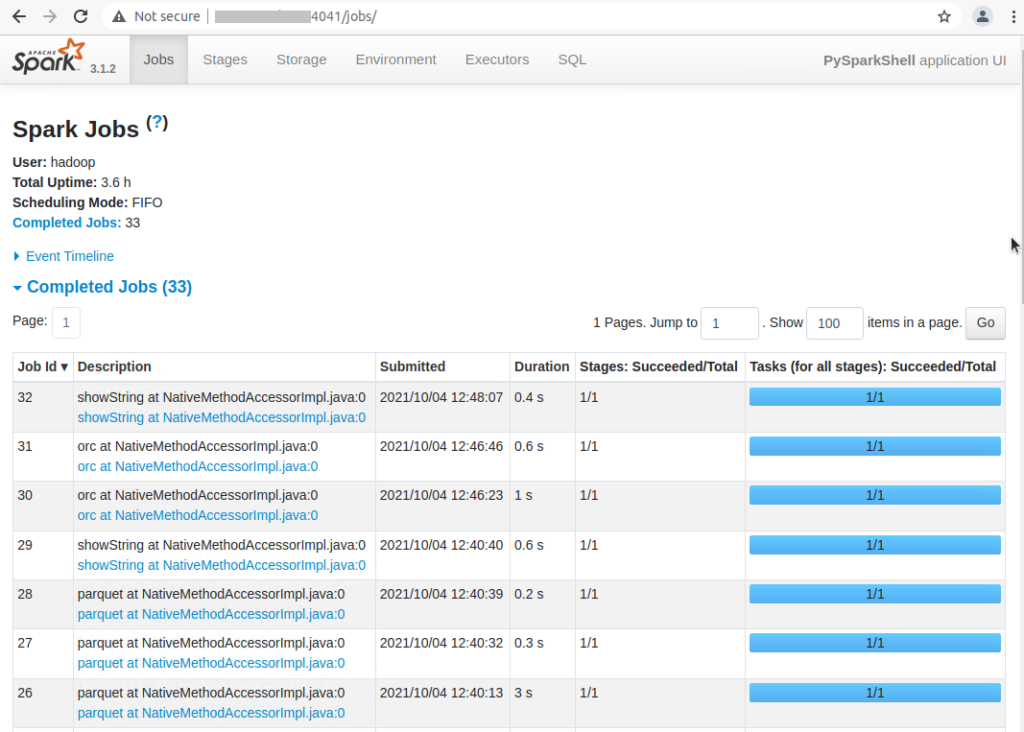
▼4. 参考情報
以上です。参考になりましたら幸いです。