自己投資の一つとしてチャレンジしている内容を Blog で公開しています。今回は Hadoop で MapReduce を利用した分散処理を行うため、Apache Hadoop クラスターを OS ubuntu 20.04.1 を使って 3 Node で構築してみたいと思います。
————————————
▼1. Apache Hadoop とは?
————————————
Apache Hadoop とは、複数のマシンを利用し、大量のデータ処理やデータ分析に利用できるオープンソースのフレームワークです。分散処理をする Node を複数のマシンにスケールアウトすることも可能です。Apache Hadoop クラスタでは、Apache Hadoop Distributed File System (HDFS) や Apache Hadoop Yet Another Resource Negotiator (YARN) が利用でき、Apache Hadoop MapReduce を利用した並列処理なども可能です。(参考情報) Apache Hadoop

————————————
▼2. Apache Hadoop のインストール
————————————
2-1. 3 台の Ubuntu 20.04.01 LTS x64 を用意します。
1 台は司令塔の役割を持つ Master node (name node) として、残り 2 台は分散処理の役割を担う Worker node (data node) として Ubuntu のマシンを用意します。今回は Windows の Hyper-V 上にマシンを作成しています。
2-2. すべてのマシンにて、NIC を追加し Private IP Address を割り当てます。各ノード (マシン) の hosts ファイルは以下のようになります。すべてのマシンで設定します。
(例) /etc/hosts
127.0.0.1 localhost
10.0.0.1 masternode
10.0.0.2 datanode1
10.0.0.3 datanode2(**) IPv6 のアドレスはコメントアウトしておきましょう。Master node から Worker node が認識さない事象が発生します。(参考情報) azure – hadoop cluster, datanode cannot run and 0 node are excluded – Stack Overflow
2-3. すべてのマシンにて、hadoop のユーザーを作成し管理者の権限を付与します。Ubuntu の UI の Settings にある Users から設定可能です。以降 hadoop のユーザーで設定を進めます。またすべてのマシンに SSH もインストールします。
sudo apt-get install openssh-server2-4. Master node にて SSH キーを生成します。Hadoop ユーザーが SSH の接続の際利用する、キーペア(公開鍵、秘密鍵)での認証を行うため SSH key を作成します。
- Master node に hadoop ユーザーでログインし、terminal から以下のコマンドを実行します。キーの保存先など既定のままで進み、パスワードの設定では、何も入れず、Enter を押して設定を進めます。
ssh-keygen -t rsa - 生成した公開鍵を確認します。
less /home/hadoop/.ssh/id_rsa.pub - 作成した公開鍵を承認済みのキーに追加し権限を付与します。
cat ~/.ssh/master.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys - 生成した公開鍵を各 DataNode にコピーします。
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@datanode1
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@datanode22-5. すべてのマシンにて、Hadoop のパッケージをダウンロードし解凍します。
cd
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar -xzvf hadoop-3.3.1.tar.gz
mv hadoop-3.3.1 hadoop2-6. すべてのマシンにて、環境変数の設定を行います。
/home/hadoop/.profile の末尾に以下を追記します。
PATH=/home/hadoop/hadoop/bin:/home/hadoop/hadoop/sbin:$PATH/home/hadoop/.bashrc の末尾に以下を追記します。$HADOOP_HOME は /home/hadoop/hadoop/ としています。
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin2-7. すべてのマシンにて、zulu の Java 8 openjdk x64 をインストールします。
mkdir /usr/lib/jvm/
cd /usr/lib/jvm/
sudo wget https://cdn.azul.com/zulu/bin/zulu8.54.0.21-ca-jdk8.0.292-linux_x64.tar.gz
sudo tar -xzvf zulu8.54.0.21-ca-jdk8.0.292-linux_x64.tar.gz
mv zulu8.54.0.21-ca-jdk8.0.292-linux_x64 java-8-openjdk-x64
sudo vi /etc/profile.d/java_home.sh/etc/profile.d/java_home.sh には以下記載します。
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-x64/## 設定を反映
source /etc/profile.d/java_home.sh
## JAVA_HOME の環境変数がが正しく設定されたか確認
echo $JAVA_HOME2-8. すべてのマシンにて、hadoop-env.sh の末尾にも JAVA_HOME の環境設定を指定してます。
/home/hadoop/hadoop/etc/hadoop/hadoop-env.sh に以下を追加。
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-x64/2-9. すべてのマシンにて、以下の設定を行います。
2-9-1. core-site.xml にて Name Node の場所を指定します。
/home/hadoop/hadoop/etc/hadoop/core-site.xml に以下を追加
(例) /etc/hosts にした master node の FQDN を value に記載する。今回は masternode と記載。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://masternode:9000</value>
</property>
</configuration>2-9-2. HDFS で利用するパス(フォルダ)を作成します。
mkdir /home/hadoop/data/nameNode/
mkdir /home/hadoop/data/dataNode/2-9-3. hdfs-site.xml にて HDFS のパスを指定します。
/home/hadoop/hadoop/etc/hadoop/hdfs-site.xml に以下を追加。nameNode, dataNode のパスは 2-9-2 で作成したパスを指定します。
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>2-9-4. mapred-site.xml にて Job Scheduler として YARN を指定します。
/home/hadoop/hadoop/etc/hadoop/mapred-site.xml に以下を追加。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>2-9-5. yarn-site.xml にて YARN を設定します。yarn.resourcemanager.hostname の IP Address は /etc/hosts で指定した master node の IP を指定します。
/home/hadoop/hadoop/etc/hadoop/yarn-site.xml に以下を追加。
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.0.0.1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>2-9-6. worker node (data node) を指定します。
/home/hadoop/hadoop/etc/hadoop/workers に以下を追加。worker node の名前は /etc/hosts で指定した worker node の FQDN となります。
datanode1
datanode22-10. HDFS の実行と監視
2-10-1. Master node にて、HDFS のフォーマット
hdfs namenode -format2-10-2. HDFS の起動
(**) 停止は stop-dfs.sh
start-dfs.sh2-10-3. HDFS の監視
hdfs dfsadmin -report2-10-4. Dashboard からも Hadoop の情報を確認することができます。
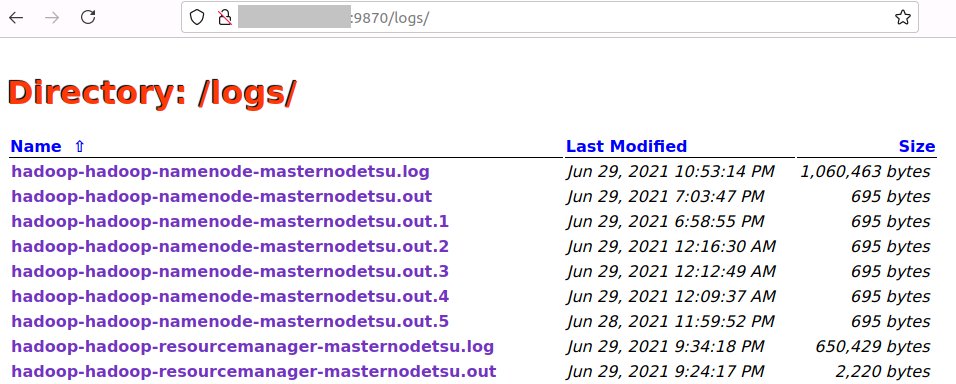
Hadoop の設定や $HADOOP_HOME/logs 配下にある Hadoop のログや HDFS の監視ができます。
URL (例) : http://masternode:9870
(**) Dashboard の URL に含まれる “masternode” は /etc/hosts で指定した master node の FQDN もしくは IP Address となります。
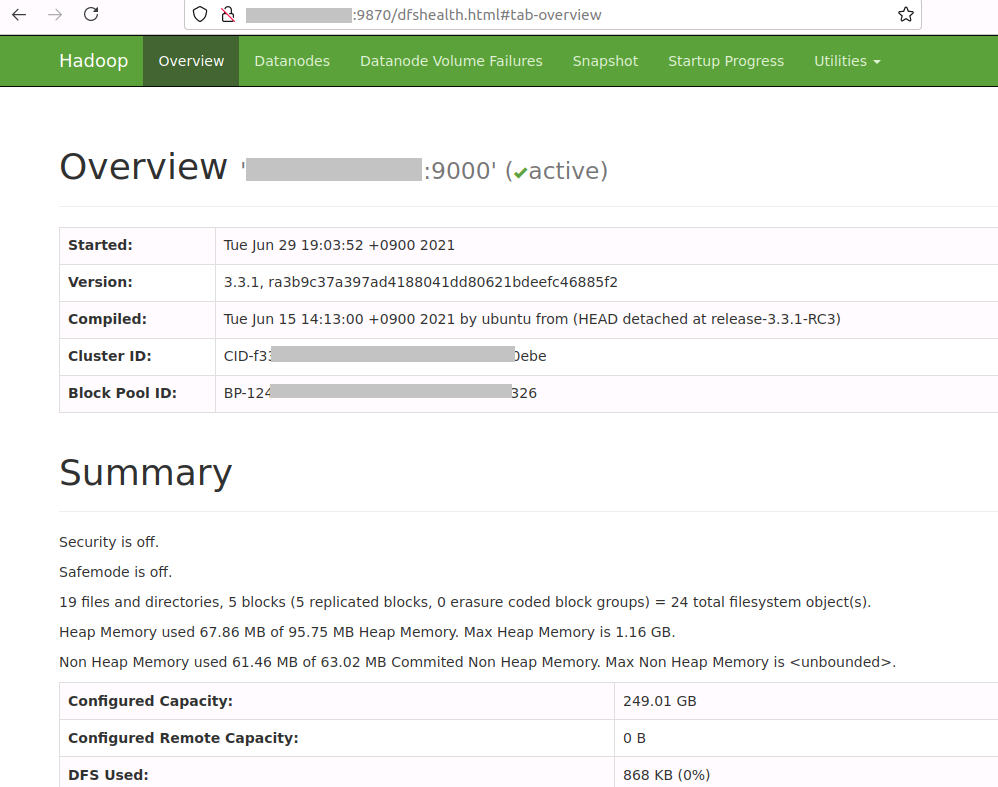
Hadoop のログなど確認できます。
————————————
▼3. HDFS の利用
————————————
コマンドラインから Hadoop Distributed File System (HDFS) へアクセスすることができ、ls コマンド、mkdir コマンドなど linux で実行できるコマンドが HDFS に対して実行できます。
(参考情報) Apache Hadoop 3.3.1 – HDFS Commands Guide
3-1. ホームディレクトリの作成後、その配下にディレクトリを作成
hdfs dfs -mkdir -p /user/hadoop
hdfs dfs -mkdir appbox3-2. ファイルをディレクトリにコピーします。ファイルは何でもいいです。どこかのサイトからダウンロードした Readme.txt などでもいいです。あとで行う wordcount の入力のファイルとして利用します。
hdfs dfs -put applicationlog.txt appbox3-3. コピーしたファイルの確認
hdfs dfs -ls appbox
## 出力結果の例 ##
Found 1 items
-rw-r--r-- 1 hadoop supergroup 431986 2021-06-28 10:00 appbox/applicationlog.txt
————————————
▼4. YARN の利用
————————————
Hadoop でのデータ処理は YARN により管理されます。YARN を介して Java のアプリケーションを実行できます。以下 hadoop インストール時に同梱された mapreduce を行う hadoop-mapreduce-example-3.3.1.jar を実行してみます。
4-1. Master Node にて YARN を起動
(** 停止は stop-yarn.sh)
start-yarn.sh4-2. MapReduce を利用し文字をカウントする sample の jar を実行し、3-2 で用意した applicationlog.txt を入力とし、結果を output2 のフォルダへ出力します。
yarn jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-example-3.3.1.jar wordcount "appbox/applicationlog.txt" output24-3. output2 に出力された結果は以下の hdfs のコマンドで確認できます。
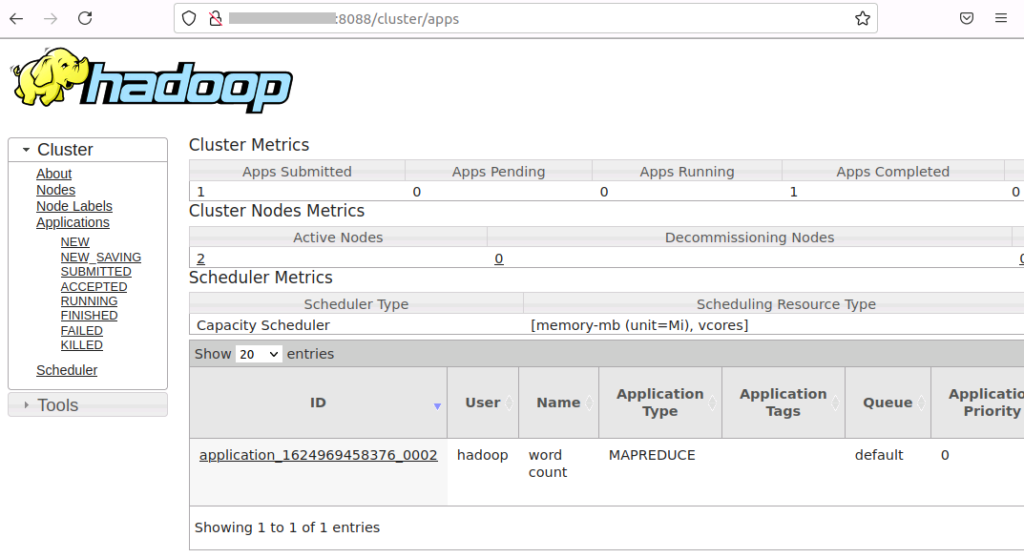
hdfs dfs -cat output2/part-r-00000 | less4-4. YARN UI http://masternode:8088 では、実行した application が成功したか失敗したかの確認や、エラーの詳細を含む application のログを確認することができます。
(**) Dashboard の URL に含まれる masternode は /etc/hosts で指定した master node の FQDN もしくは IP Address となります。
————————————
▼4. 参考情報
————————————
(1) Apache Hadoop
(2) How to Install and Set Up a 3-Node Hadoop Cluster | Linode
以上です。参考になりましたら幸いです。